Using Samba
Robert Eckstein, David Collier-Brown, Peter Kelly1st Edition November 1999
1-56592-449-5, Order Number: 4495
416 pages, $34.95
|
|
Using SambaRobert Eckstein, David Collier-Brown, Peter Kelly1st Edition November 1999 1-56592-449-5, Order Number: 4495 416 pages, $34.95 |
B.3 Sizing von Sambaservern
Sizing ist eine Möglichkeit, sich vor Engpässen zu schützen, bevor sie auftreten. Der vorzügliche Weg für diese Tätigkeit ist zu wissen, wie viele Anfragen pro Sekunde oder wie viele Kilobytes pro Sekunde die Clients brauchen, und sicherzustellen, dass alle Komponenten des Servers wenigstens für diese Zahl sorgen.
B.3.1 Die Engpässe
Die drei Flaschenhälse, die dich beunruhigen sollten, sind CPU, Disk-I/O und das Netzwerk. Für die meisten Maschinen sind CPU selten ein Engpass. Eine einzelne Sun SPARC 10 CPU kann zwischen 700 und 800 I/O-Operationen in einer Sekunde starten (und beenden) und gibt annähernd 5.600 bis 6.400 KB/s Durchsatz, wenn die Daten durchschnittlich rund 8 KB/s (eine übliche Puffergröße) betragen. Ein einzelner Intel Pentium 133 kann weniger verarbeiten, nur wegen eines etwas langsameren Cache und langsamere Bus-Interfaces, nicht infolge von Mangel an CPU-Leistung. Zweck-konstruierte Pentiumserver wie einige Compaq-Server können 700 Operationen pro CPU auf bis zu vier CPUs starten.
Zu wenig Speicher kann andererseits leicht ein Engpass sein; jeder Sambaprozess braucht zwischen 600 und 800 KB auf Intel Linux und mehr auf RISC CPUs. Wenig Speicher verursacht eine Steigerung von Zugriffen auf den virtuellen Speicher und daher eine Performance-Einbuße. Auf Solaris, wo es gemessen wurde, braucht smbd 2,6 MB für Programm und freigegebene Bibliotheken plus 768 KB für jeden angeschlossenen Client. nmbd beansprucht 2,1 MB plus 496 KB KB extra für seinen (Einzel-) Hilfsprozess.
Festplatten werden immer Flaschenhälse bei einer bestimmten Zahl von I/O-Operationen pro Sekunde: jede 7200 UpM-SCSI-Platte ist fähig, 70 Operationen pro Sekunde bei einem Durchsatz von 560 KB/s durchzuführen; eine 4800 UpM-Platte führt weniger als 50 bei einem Durchsatz von 360 KB/s durch. Eine einzelne IDE-Platte macht noch weniger. Wenn die Platten unabhängig sind oder zusammengeschlossen in einer RAID 1-Konfiguration, wird jede 400 bis 560 KB/s erreichen und linear ansteigen, wenn du mehr anschließt. Beachte, dass das nur für RAID 1 gilt. Andere RAID-Level als 1 (Striping) fügen extra Overhead dazu.
Ethernets (und andere Netzwerke) sind offensichtlich ein Engpass: ein 10 Mb/s (Mega bits/Sekunde)-Ethernet erledigt rund 1100 KB/s (Kilo bytes/s) unter Verwendung von 1500-Byte-Paketen. Ein 100 Mb/s-Fast Ethernet bildet einen Engpass unter 65.000 KB/s mit derselben Paketgröße. FDDI wird bei 155 Mb/s annähernd 6.250 KB/s erreichen, bietet aber gute Dienste bei 100 Prozent Laden und Übertragen viel größerer Pakete (4 KB).
ATM sollte viel besser sein, aber während des Schreibens dieses Buches war es zu neu, um zur Höchstform aufzulaufen; es scheint rund 7.125 Mb/s unter Verwendung von 9 KB-Paketen zu bringen.
Natürlich können andere Engpässe auftreten: mehr als eine IDE-Platte pro Controller ist nicht gut, wie es auch für mehr als drei 3600-SCSI-I-Platten pro Slow/Narrow-Controller oder mehr als drei 7200-SCSI-II-Platten pro Fast/Wide-Controller gilt. RAID ist ebenfalls langsam, weil es zweimal so viel Schreibvorgänge erfordert als unabhängige Platten oder RAID 1.
Nach dem zweiten Satz Ethernets und dem zweiten Plattencontroller beginnt das Ärgernis mit der Bus-Bandbreite, besonders wenn du ISA/EISA-Busse verwendest.
B.3.2 Engpässe verringern
Auf Grund der obigen Information können wir ein Modell ausarbeiten, das uns die maximalen Fähigkeiten einer gegebenen Maschine darstellt. Die meisten Daten sind aus Brian Wong's Configuration and Capacity Planning for Solaris Servers [1] entnommen, daher gibt es eine geringe Voreingenommenheit für Sun in unseren Beispielen.
Ein warnendes Wort: das ist kein komplettes Modell. Nimm nicht an, dass dieses Modell jeden Flaschenhals vorhersagt oder auch innerhalb 10 Prozent in seinen Schätzungen liegt. Ein Modell, die Performance vorauszusagen, anstatt eines, dich vor Engpässen zu warnen, würde viel komplexer sein und würde Regeln enthalten wie "nicht mehr als drei Platten pro SCSI-Kette". (Ein gutes Buch an realen Modellen ist Raj Jain's The Art of Computer Systems Performance Analysis.[2]) Mit dieser Warnung stellen wir das System in Figur B.2 vor.
[2] Siehe Jain. Raj, The Art of Computer Systems Performance Analysis, New York, NY (John Wiley and Sons), 1991, ISBN 0-47-150336-3.
Figur B.2: Datenfluss durch einen Sambaserver mit möglichen Engpässen
Der Fluss der Daten sollte klar sein. Bei einem Lesevorgang z.B. fließen Daten von der Platte, über den Bus, durch die CPU oder an ihr vorbei und zur Netzwerk-Interfacekarte (NIC). Dann werden sie in Pakete zerlegt und über das Netzwerk versandt. Unsere Strategie besteht hier darin, den Daten durch das System zu folgen und zu entdecken, welche Flaschenhälse sie drosseln. Glaub es oder nicht, es ist eher leicht, einen Satz Tabellen herzustellen, welche die höchste Performance von üblichen Platten, CPUs und Netzwerkkarten auf einem System auflistet. Das ist also genau das, was wir machen.
Nehmen wir ein konkretes Beispiel her: eine Linux Pentium 133 MHz-Maschine mit einer einzelnen 7200 UpM-Festplatte, ein PCI-Bus und eine 10-Mb/s-Ethernetkarte. Das ist ein vollkommen akzeptabler Server. Wir beginnen mit Tabelle B.2, welche die Festplatte beschreibt - der erste potentielle Flaschenhals im System.
Tabelle B.2: Platten-Durchsatz Platte UpM
I/O-Operationen/Sekunde
KB/Sekunde
7200
70
560
4800
60
480
3600
40
320
Platten-Durchsatz ist die Zahl an Daten-Kilobytes, die eine Platte in der Sekunde übertragen kann. Sie wird berechnet aus der Zahl von 8 KB I/O-Operationen pro Sekunde, die eine Platte durchführen kann, welche in der Leistung stark beeinflusst ist von den Platten-UpM und der Bit-Dichte. In der Folge ergibt sich die Frage: wie viele Daten können unter den Schreib/Leseköpfen in einer Sekunde passieren? Mit einer einzelnen 7200 UpM-Platte gibt uns der Beispiels-Server 70 I/O-Operationen pro Sekunde bei ungefähr 560 KB/s.
Der zweite mögliche Flaschenhals ist die CPU. Die Daten fließen auf modernen Maschinen nicht wirklich durch die CPU, daher müssen wir den Durchsatz ein wenig indirekt berechnen.
Die CPU muss I/O-Requests ausgeben und die zurückkommenden Interrupts verarbeiten, dann die Daten über den Bus zur Netzwerkkarte transferieren. Von vielen vergangenen Experimenten wissen wir, dass der Overhead, der das Verarbeiten beherrscht, ständig im Dateisystem-Code ist, daher können wir die andere gerade laufende Software ignorieren. Wir berechnen den Durchsatz, indem wir nur die (gemessene) Zahl von Datei-I/O-Operationen pro Sekunde, die eine CPU verabeiten kann, mit denselben 8 K durchschnittlicher Requestgröße multiplizieren. Dies ergibt uns die in Tabelle B.3 gezeigten Resultate.
Tabelle B.3: CPU-Durchsatz CPU
I/O Operationen/Sekunde
KB/Sekunde
Intel Pentium 133
700
5.600
Dual Pentium 133
1.200
9.600
Sun SPARC II
660
5.280
Sun SPARC 10
750
6.000
Sun Ultra 200
2.650
21.200
Nun vergleichen wir die Platte zusammen mit der CPU: im Linux-Beispiel haben wir eine einzelne 7200 UpM-Platte, die uns 560 KB/s liefern kann, und eine CPU mit der Fähigkeit, 700 I/O-Operationen zu starten, was uns 5600 KB/s bringen kann. So weit, wie du erwarten würdest, ist unser Flaschenhals offensichtlich die Festplatte.
Der letzte potentielle Engpass ist das Netzwerk. Wenn die Netzgeschwindigkeit unter 100 Mb/s beträgt, ist die Netzgeschwindigkeit der Flaschenhals. Danach bremst uns noch wahrscheinlicher die Konstruktion der Netzwerkkarte. Tabelle B.4 zeigt uns den durchschnittlichen Durchsatz vieler Typen von Datennetzwerken. Obwohl die Netzwerk-Geschwindigkeit gewöhnlich in Bits pro Sekunde gemessen wird, listet Tabelle B.4 Bytes pro Sekunde auf, um den Vergleich mit der Platte und der CPU (Tabelle B.2 und Tabelle B.3) leichter zu machen.
Tabelle B.4: Netzwerk-Durchsatz Netzwerktyp
KB/Sekunde
ISDN
16
T1
197
Ethernet 10m
1.113
Token ring
1.500
FDDI
6.250
Ethernet 100m
6.500[3]
ATM 155
7.125a
[3] Diese werden sich vergrößern. Crays, Sun Ultras und DEC/Compaq Alphas z.B. haben diese Zahlen schon verbessert.
In dem laufenden Beispiel haben wir einen Engpass bei 560 KB/s auf Grund der Platte. Tabelle B.4 zeigt uns, dass ein Standard-Ethernet mit 10 Megabit pro Sekunde (1.113 KB/s) weit schneller als die Platte ist. Daher ist die Festplatte immer noch der begrenzende Faktor. (Dieses Szenario ist übrigens häufig üblich.) Gerade durch den Blick auf die Tabellen können wir voraussagen, dass kleine Server keine CPU-Probleme haben werden und dass große mit mehreren CPUs Striping und mehrere Ethernets unterstützen, lange bevor ihnen die CPU-Leistung ausgeht. Das ist wirklich genau das, was passiert.
B.3.3 Praktische Beispiele
Ein Beispiel aus Configuration and Capacity Planning for Solaris Servers (Wong) zeigt, dass ein Dual-Prozessor SPARCstation 20/712 mit vier Ethernets und sechs 2,1 GB-Platten seine ganze Zeit mit Warten auf die Platten verbringt, um irgendwelche Daten zurückzusenden. Wenn er mit Disks geladen wurde (Brian Wong schlägt so viel wie 34 von ihnen vor), würde er noch ungefähr 1.200 KB/s von den Ethernetkarten gefasst haben. Um die Performance zu bekommen, zu der die Maschine fähig ist, müssten wir mehrere Ethernets, ein 100 Mb/s-Fast Ethernet oder ein 155 Mb/s-FDDI konfigurieren.
Die Reihe, die du durcharbeiten musstest, um diese Schlussfolgerung zu erhalten, schaut etwa aus wie Tabelle B.5.
Tabelle B.5: Tuning eines mittelgroßen Servers Maschine
Platten-Durchsatz
CPU-Durchsatz
Netzwerk-Durchsatz
Wirklicher Durchsatz
Dual SPARC 10, 1 Platte
560
6.000
1.113
560
5 Platten zusätzlich
3.360
6.000
1.113
1.113
3 Ethernets zusätzlich
3.360
16.000
4.452
3.360
Wechseln zur Verwendung eines 20-Platten-Arrays
11.200
6000
4.452
4.452
Verwende ein Dual-100 Mb/s-Ethernet
11.200
6000
13.000
11.200
Am Anfang ist die Platte der Flaschenhals mit nur 560 MB/s vorhandenem Durchsatz. Als Lösung geben wir fünf andere Platten dazu. Das gibt uns mehr Durchsatz auf den Platten als auf dem Ethernet, also wird dann das Ethernet das Problem. Während wir infolgedessen die Erweiterung fortsetzen, wechseln wir einige Male zwischen diesen beiden hin und her. Indem du Platten, CPUs und Netzwerkkarten hinzufügst, verändert sich der Engpass. Bei der Strategie ist es absolut erforderlich, mehr Equipment hinzuzufügen, um jeden Flaschenhals zu vermeiden versuchen, bis du deine Wunsch-Performance erreichst oder du (bedauerlicherweise) entweder nichts mehr einbauen kannst oder dir das Geld ausgegangen ist.
Unsere Erfahrung hält sich aus dieser Art von Kalkulation heraus; ein großer SPARC 10 Fileserver, den ein Autor betrieb, war durchaus fähig, ein Ethernet plus etwa ein Drittel eines FDDI-Rings zu bewältigen , wenn er zwei Prozessoren verwendet. Es funktioniert beinahe auch mit einem Einzel-Prozessor, wenn auch mit einem schnellen Betriebssystem und vernünftiger Über-Optimierung.
Derselbe Prozess trifft auf andere Sorten für diesen Zweck konstruierte Server zu. Wir fanden dieselben Regeln bei DECstation 2100 wie bei den neuesten Alphas oder Compaqs, alten MIPS 3350 und neuen SGI O2 angewandt. Im Allgemeinen hat eine Maschine, die Multi-CPU-Serverkonfigurationen bietet, genug Bus-Bandbreite und CPU-Leistung, um einen Engpass bei Festplatten-I/O zuverlässig auszugleichen, wenn sie Fileservice betreibt. Wie einer hoffen würde, der die Kosten berücksichtigt!
B.3.4 Wie viele Clients kann Samba betreuen?
Na ja, das hängt ganz davon ab, wie viele Daten jeder User konsumiert. Ein kleiner Server mit drei SCSI-1-Platten, der etwa 960 KB/s Daten bieten kann, unterstützt zwischen 36 und 80 Clients in einer gewöhnlichen Büroumgebung, wo alle typischerweise gleich große Spreadsheets oder Textverarbeitungs-Dokumente laden und speichern (36 Clients × 2.3 Transfers/Sekunde × 12k Datei 1 MB/s).
Auf demselben Server in einer Entwicklungsumgebung mit Programmierern, die einen ziemlich umfangreichen Edit-Compile-Testzyklus durchführen, kann einer leicht Requests für 1 MB/s erleben, was den Server auf 25 oder weniger Clients beschränkt. Um darauf ein wenig weiter einzugehen, ein gedachtes System, dessen Clients alle 10 MB/s brauchen, wird eine schwache Leistung bringen, egal wie groß ein Server ist, wenn sie alle auf einem 10 MB/s-Ethernet hängen. Und so weiter.
Wenn du nicht weißt, wieviel Daten ein durchschnittlicher User konsumiert, kannst du die Größe deiner Sambaserver einrichten, indem du sie existierenden NFS-, Nerware- oder LAN Manager-Servern nachbildest. Du solltest besonders darauf achten, dass die neuen Server so viele Platten und Disk-Controller haben wie diejenigen, die du kopiert hast. Diese Technik wird entsprechend "punt and hope" (auswerfen und hoffen) genannt.
Wenn du weißt, wie viele Clients ein existierender Server unterstützen kann, bist du in einer viel besseren Lage. Du kannst den Server analysieren, um herauszufinden, was seine maximale Kapazität ist, und das verwenden, um zu schätzen, wie viele Daten sie anfordern müssen. Wenn z.B. die Betreuung der Home-Verzeichnisse von 30 PCs von einem PC-Server mit zwei IDE-Platten einfach zu langsam und von 25 Clients etwa richtig ist, dann kannst du sicher annehmen, dass du eher vom Ethernet I/O (annähernd 375 KKB) als von der Platte (bis zu 640 KB) beengt wirst. Wen das so ist, dann kannst du entscheiden, dass die Clients 15 KB/s (das ist 375/25) im Durchschnitt erfordern.
Die Unterstützung eines neuen Labors mit 75 Clients heißt, dass du 1.125 KB/s brauchst, über mehrere (vorzugsweise drei) Ethernets ausgedehnt, und einen Server mit mindestens drei 7200 UpM-Platten und eine CPU mit der Fähigkeit, nicht nachzulassen. Diese Erfordernisse können von einem Pentium 133 oder höher mit der Bus-Architektur getroffen werden, um sie alle mit voller Geschwindigkeit zu betreiben (z.B. PCI).
Ein maßgefertigter PC-Server oder eine Multiprozessor-fähige Arbeitsstation wie ein Sun Sparc, ein DEC/Compaq Alpha, ein SGI oder dergleichen, könnte leichter aufgerüstet werden als eine Maschine mit Fast-Ethernet plus einem Switching-Hub, um die Client-Maschinen auf einzelnen 10 MB/s-Ethernets zu betreiben.
B.3.4.1 Wie schätzt man
Wenn du keine Idee von allem hast, was du brauchst, ist es am besten, auf Grund der Erfahrung von jemand anderem zu schätzen versuchen. Jede einzelne Client-Maschine kann einen Durchschnitt von weniger als 1 (normaler PC oder Mac für Verkauf/Buchhaltung) bis so viel wie 4 I/O pro Sekunde (schnelle Arbeitsstation für große Applikationen) erreichen. Eine schnelle Arbeitsstation, die einen Kompiler ausführt, kann zum Glück durchschnittlich 3-4 MB/s bei Daten-Transfer-Requests erreichen, und ein gedachtes System kann noch mehr fordern.
Unsere Empfehlung? Spioniere bei irgendwelchen Leuten mit einer ähnlichen Konfiguration und versuche deren Bandbreiten-Bedarf aus ihren Flaschenhälsen und der Lautstärke der Schreie ihrer User zu schätzen. Wir empfehlen auch Brian Wong's Configuration and Capacity Planning for Solaris Servers. Obwohl er vornehmlich Sun Solaris in seinen Beispielen verwendet, seine Flaschenhälse sind Platten und Netzwerkkarten, die unter den größeren Anbietern gängig sind. Seine Tabellen für FTP-Server kommen dem auch sehr nahe, was wir für Sambaserver berechneten und bilden einen guten Startpunkt.
B.3.5 Formulare zum Messen
Tabelle B.6 und Tabelle B.7 sind leere Tabellen, die du zum Kopieren und zum Eintragen der Daten verwenden kannst. Die Flaschenhals-Berechnung im vorigen Beispiel kann in einem Rechenblatt oder manuell mit Tabelle B-8 erledigt werden. Wenn Samba so gut wie oder besser als FTP ist und wenn es keine einzelnen Testläufe gibt, die sich sehr vom Durchschnitt unterscheiden, hast du ein gut konfiguriertes System. Wenn Loopback nicht viel schneller als alles andere ist, hast du ein Problem mit deiner TCP/IP-Software. Wenn beide, FTP und Samba, langsam sind, hast du wahrscheinlich ein Problem mit deinem Netzwerk: eine defekte Ethernetkarte verursacht es, indem man zufällig eine Ethernetkarte auf Halb-Duplex setzt, wenn sie nicht an einen Halb-Duplex-Hub angeschlossen ist. Vergiss nicht, dass CPU- und Platten-Geschwindigkeiten üblicherweise in Bytes gemessen werden, Netzwerk-Geschwindigkeiten in Bits.
Wir haben Spalten für Bytes und Bits in die Tabellen aufgenommen. In der letzten Spalte vergleichen wir die Ergebnisse mit 10 Mb/s, weil das die Geschwindigkeit eines traditionellen Ethernets ist.
Tabelle B.6: Ethernet-Interface zum gleichen Host: FTP Lauf Nr.
Größe in Bytes
Zeit (s)
Bytes/s
Bits/s
% von 10 Mb/s
1
2
3
4
5
Durchschnitt:
Abweichung:
Tabelle B.7: Ethernet-Interface zum gleichen Host: FTP Lauf Nr.
Größe in Bytes
Zeit (s)
Bytes/s
Bits/s
% von 10 Mb/s
1
2
3
4
5
Durchschnitt:
Abweichung:
Tabelle B.8: Flaschenhals-Rechentabelle CPU
CPU-Durchsatz
Zahl der Platten
Disk-Durchsatz
Zahl der Netzwerke
Netzwerk-Durchsatz
Total-Durchsatz
In Tabelle B.8:
CPU-Durchsatz = (KB/Sekunde von Figur 6-5) × (Zahl der CPUs)
Platten-Durchsatz = (KB/Sekunde von Figur 6-4) × (Zahl der Disks)
Netzwerk-Durchsatz = (KB/Sekunde von Figur 6-6) × (Zahl der Netzwerke)
Total-Durchsatz = min (Platten-, CPU- und Netzwerk-Durchsatz)
Ein typischer Test, in diesem Fall für ein FTP
bekommen, würde wie in Tabelle B-9 eingetragen werden:
Tabelle B.9: Ethernet-Interface zum gleichen Host: FTP Lauf Nr.
Größe in Bytes
Zeit (s)
Bytes/s
Bits/s
% von 10 Mb/s
1
1812898
2.3
761580
2
2.3
767820
3
2.4
747420
4
2.3
760020
5
2.3
772700
Durchschnitt:
2.32
777310
6218480
62
Abweichung:
0.04
Das von uns früher verwendete Sparc-Beispiel würde wie Tabelle B-10 aussehen.
 |
 |
 |
| B.2 Samba-Tuning |
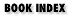 | C. Schnell-Referenz für Samba-Konfigurationsoptionen |
© 1999, O'Reilly & Associates, Inc.